Por: Henry Romero
Reconocimiento Facial de Amazon
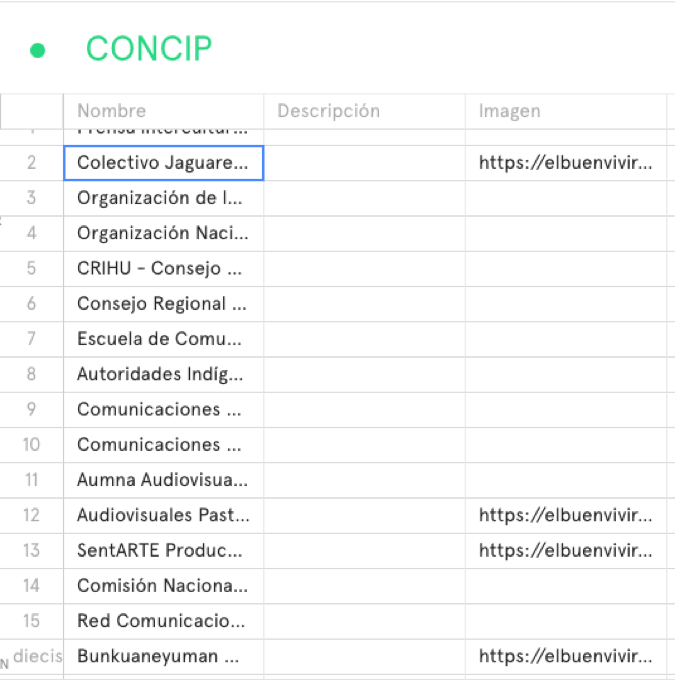
¿Qué se sabe / imagina colectivamente sobre su estudio de caso / objeto?
Según la información divulgada por la propia compañía la tecnología de reconocimiento facial Amazon Rekognition permite identificar objetos, personas, texto, escenas, actividades en imágenes y videos e identificar contenido inapropiado, con lo que es posible analizar y comparar rostros con alta precisión para diversos usos, entre los que se destaca la verificación de usuarios, conteo de personas y la seguridad pública.

¿Qué papel juega en los imaginarios contemporáneos? ¿En fantasías (o pesadillas)? ¿Qué tipo de narrativas nacionales lo utilizan? ¿Cómo aparece en el entretenimiento? ¿Qué otras grandes narrativas, historias y asociaciones fuertes lo involucran?
En los imaginarios contemporáneos el uso de esta tecnología se refleja como una herramienta de utilidad práctica muy potente que muestra los desarrollos en inteligencia artificial y la detección de rostros, objetos o situaciones que al ser valorados de acuerdo a determinados fines pueden direccionar la acción e intervenir ya sea en ámbitos privados o públicos.
La prueba de Amazon Rekognition por parte de la Unión Americana de Libertades Civiles para denunciar los riesgos y el sesgo racial de este software, desencadenó una narrativa contraria a la oficial, señalando el peligro de las fallas cuando esta tecnología es aplicada para fines policivos. Sus márgenes de error conducen a injusticias que de no ser por la aplicación no se presentarían, dado el sesgo con el que se puede alimentar el software o los sesgos del propio algoritmo con el que opera y aprende tal tecnología.

Al evidenciar los errores de Rekognition se pudo llamar la atención sobre los riesgos de la misma solo por el estatus de los datos de las personas sobre las que se aplicó la herramienta. En cualquier caso este hecho dio buenas razones para determinar dichos riesgos y hacer consciente a la sociedad del peligro cuando se usa sin las correcciones necesarias, creando una narrativa muy diferenciada a la oficial. Su impacto fue tan significativo que la propia Amazon reconoce recientemente los posibles riesgos en el uso policial y suspendió el uso con tales fines de manera indefinida.
Un análisis crítico de la tecnología no puede ser una actividad solamente académica, el ejercicio de la ACLU con los sesgos y fallos que pudo haber tenido, evidenció que la Inteligencia artificial no es autónoma y no surge de la nada, al ser un artefacto humano reproduce las imperfecciones humanas e injusticia, por tanto las narrativas de precisión y todopoderosa alrededor de la tecnología, son solo narrativas que ocultan consecuencias que inintencionadamente se pueden producir sin que se haga un análisis socio humano a profundidad. La crítica sirvió además sirve para una transformación y corrección cuando la tecnología se desborda a usos impensados.
En términos de entretenimiento y de la recepción no especializada, la tecnología de reconocimiento facial al haber sido empleada por muchas aplicaciones se presenta como un avance más de IA que por ejemplo facilita control de acceso a eventos deportivos de hinchas no deseados, prevención del terrorismo, elección de contenidos inapropiados, coincidencias en aplicaciones de citas, decisiones financieras y de seguros por verificación biométrica, entre muchas otras, lo que refuerza una narrativa de progreso, desarrollo y avance.
¿Cuáles son las historias “oficiales” incrustadas en / alrededor de su objeto? ¿Qué se sabe generalmente sobre cómo se inventó, cuándo y quién lo inventó? ¿Existen versiones diferentes y competitivas de sus historias? ¿Quién cuenta o llega a “ver” estas historias? ¿Quién le da forma? ¿Cómo ha viajado históricamente? ¿Cómo estos ayudan a constituirlo? ¿Qué otras grandes narrativas hacen referencia a él y cómo importan esas referencias?
Amazon Rekognition se desarrolla en 2016 por Amazon Web Services con fines de análisis y comparación de imágenes, video, rostros, etc. como un software de servicio el que en 2017 fue usado por el Sheriff del Condado de Washington para identificar los rostros de personas sospechosas y compararlos con las bases de datos propias. Este uso creativo se extendió a otro tipo de autoridades y agencias de seguridad con fines similares, pero a raíz de los errores en la identificación a partir de la comparación de rostros se crea una alerta y se evidencia la injusticia probable con el uso de esta tecnología para la detección de sospechosos de crímenes.
Las miradas alrededor de Recognition son diferenciadas porque la intencionalidad de esta tecnología es civil y no necesariamente se previeron los usos que se le han dado y que se le podrán dar en el futuro. Desde la propia Amazon destacan su potencialidad, como es natural, y la defienden de los críticos aduciendo mal uso de la herramienta de acuerdo a las recomendaciones de la propia compañía, en tanto los márgenes de error para identificar objetos no deben ser los mismos que para la identificación de rostros, como parece haber ocurrido con la prueba que denunció la ACLU ante el Congreso de los EE. UU.
Es de anotar también que no es la única compañía que ha desarrollado este tipo de software dado que tanto IBM como Microsoft han hecho lo mismo. Desde la perspectiva de mercado Recognition pudo haber estado en el momento y lugar equivocado para que su principales competidores usaran las debilidades manifiestas para aventajar a Amazon en el mercado reforzando su baja eficacia en comparación con la de ellos y capitalizaran este caso en beneficio propio.
Reflexión
El caso descrito de Amazon Recognition es uno más de desarrollo tecnológico, sus determinantes y consecuencias. En sí mismo el desarrollo de la Inteligencia Artificial y el aprendizaje que de esta se deriva es intencionalmente estratégico desde el plano corporativo y económico, pero evidencia que las estructuras que gobiernan las relaciones sociales reales condicionan tales desarrollos, que en muchos casos reproducen lo defectuosas que estas son. Los sesgos en la tecnología recrean los prejuicios sociales de diferente orden como la raza, el género, estrato social, nivel educativo, etc.; no es un asunto del uso dado o el direccionamiento de la tecnología, sino es en la configuración básica de la misma, en la lógica misma de cómo se construyen los algoritmos.
El argumento tradicional de que la tecnología es neutral y que los usos son los que la hacen nociva, es insostenible ahora dado el sesgo que se transfiere en muchos casos al funcionamiento mismo de la tecnología, por lo tanto es un imperativo, más que nunca, atender a un desarrollo tecnológico, desde sus primeras etapas, que sea integral, humano y con sentido de respeto por los derechos de las personas; aunque siempre habrá al interior de los laboratorios intereses que sobrepasan los límites sociales, legales y éticamente permitidos, cobijados con el manto de la libertad, el progreso científico y la propiedad privada. La tecnología no puede ser ni más bondadosa ni más perversa que los propios seres humanos, por tanto el control aún es nuestro.
https://aws.amazon.com/es/blogs/aws/thoughts-on-machine-learning-accuracy/
https://www.thetelegraph.com/news/article/Amazon-extiende-veda-de-reconocimiento-facial-a-16186374.phphttps://www.tecnoseguro.com/analisis/cctv/rekognition-amazon-reconocimiento-facial-investigaciones