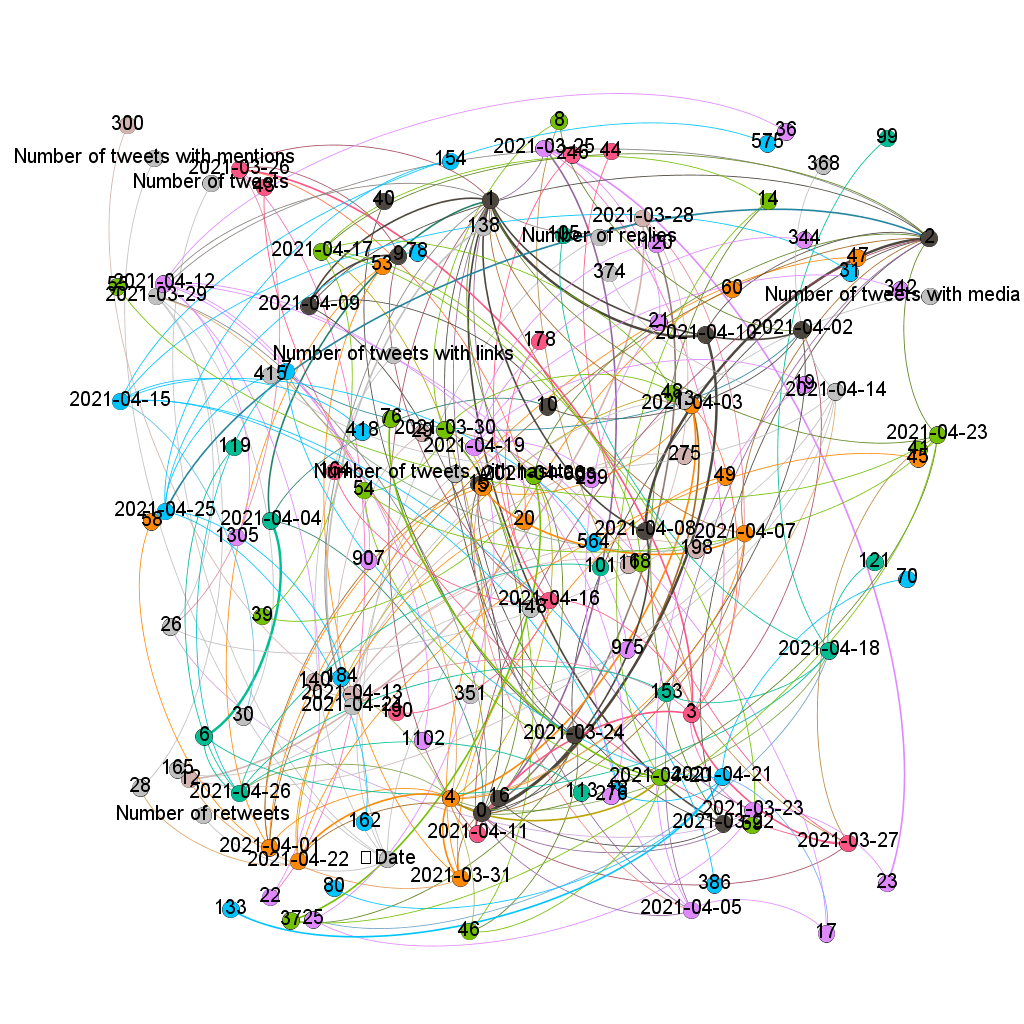
INDIRA – Plataforma basada en IA para proceso de imágenes diagnósticas
¿Qué se sabe sobre el estudio de caso?
Índigo Technologies es una compañía colombiana de desarrollo de software, que utilizan IA para procesar imágenes radiológicas para detección de varias enfermedades. La organización busca utilizar los sistemas de IA y los datos para asumir tareas repetitivas y permitir a los médicos y los pacientes poder tener un mejor trato humano, de acuerdo con el CEO.
Esta entidad desarrolló INDIRA la plataforma que ayuda a diagnósticos médicos basados en imágenes; la plataforma actualmente ayuda a diagnosticar 25 patologías entre ellas cáncer de pulmón, enfermedades cardiovasculares, trastornos en vías respiratorias. Cuando aparece el virus del COVID 19, Índigo desarrolla dentro de la plataforma el reconocimiento de patrones de este virus en el tipo de neumonía que éste produce. Como partner tecnológico Índigo trabaja con Microsoft.

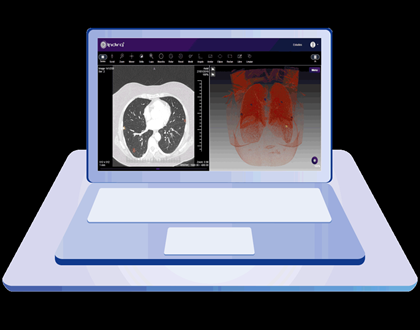
Fuente: https://indira.ai/wp-content/uploads/2019/10/indira_nodulos.gif
¿Qué papel juega en los imaginarios contemporáneos? ¿En fantasías (o pesadillas)? ¿Qué tipo de narrativas nacionales lo utilizan? ¿Cómo aparece en el entretenimiento? ¿Qué otras grandes narrativas, historias y asociaciones fuertes lo involucran?
En la actualidad el papel de este nuevo desarrollo constituye una herramienta complementaria, a la prueba PCR, desarrollada por Índigo con base en algoritmos de IA que permite en menor tiempo la entrega de resultados, con equipos de rayos x y tomógrafos disponibles en el país. Esta herramienta presenta una solución alcanzable y útil para el cuidado de la salud, que permite diagnósticos tempranos de enfermedades complejas, respiratorias y de corazón que adicionalmente ayuda al diagnóstico del COVID 19.
Teniendo otros ejemplos donde INDIRA es exitoso en su diagnóstico se cuentan con evidencias que este programa tiene una confiabilidad de 99.3% en diagnóstico de cáncer de pulmón. Con base en la experiencia de análisis de imágenes y teniendo en cuenta la afección pulmonar que genera el Coronavirus, Índigo Technologies desarrolla la solución de IA para imágenes de pulmón y la presencia de neumonías derivadas del COVID 19, para poder determinar si la persona ha sido contagiada. Si bien de acuerdo con la Organización Mundial de la Salud, la prueba aprobada es la PCR, la misma implica grandes retos en países donde el ingreso no es alto ni tampoco las capacidades instaladas son suficientes así como la logística de transporte de pruebas se convierte en desafíos adicionales.
Es realmente un avance importante en términos de prevención de enfermedades, utilizando elementos y equipos que ya se encuentran disponibles en los establecimientos médicos y que pueden ser utilizados en varias regiones del país.
Cuáles son las historias “oficiales” de su objeto? ¿Qué se sabe generalmente sobre la invención? ¿Existen versiones diferentes y competitivas de sus historias? ¿Cómo ha viajado históricamente? ¿Qué otras grandes narrativas hacen referencia a él y cómo importan esas referencias?
Índigo Technologies, tiene como objetivo de empresa: Ayudar y acompañar a clínicas y hospitales a ser altamente eficientes, para salvar y mejorar la vida de las personas a través de tecnologías innovadoras e inteligentes, prestando servicios a nivel de Latinoamérica.
Su propósito es brindar a las instituciones de salud soluciones tecnológicas e inteligentes que permitan cubrir la prestación de servicios, entregar información en tiempo real y ayudar a tomar de decisiones oportunas y acertadas con diagnósticos cada vez más precisos.
Dada la morfología de la neumonía que genera el COVID 19, el algoritmo desarrollado reconoce los patrones de afección ocasionados por el virus. Después de las pruebas realizadas se logra una certeza de 93.7% de sensibilidad y un índice de especificidad de 98.1%, lo que significa la evidencia de la ausencia del virus. De cada 100 casos con neumonías de Coronavirus, el algoritmo está en condición de identificar con exactitud a 98 de ellos.

Fuente: https://blogs.microsoft.com/latino/2020/04/16
Para el funcionamiento de la plataforma únicamente se requiere una conexión a internet lo cual es importante para las instituciones que no cuentas con equipos de diagnóstico. El servicio se presta a través de la nube de Microsoft, y se obtienen resultados en un tiempo no mayor a una hora, buscan como empresa reducir tiempos de entrega de resultados, mayor precisión de diagnósticos y un incremento de capacidades diagnósticas permanente con las tecnologías utilizadas de IA.
Como reflexión final esta es una iniciativa de IA, enfocada netamente en temas de salud y prevención de enfermedades, ya utilizada desde hace décadas pero que con algoritmos adicionales de IA permite ayudar en los diagnósticos de COVID 19.
En este caso de IA claramente se ve el objetivo de la organización de ayudar a las personas generando diagnósticos tempranos de enfermedades complejas, y donde la tecnología se ha convertido en un elemento estratégico para el cumplimiento del objetivo de organización, es un claro ejemplo del uso de la tecnología como un medio para resolver una situación, más que utilizar la tecnología como objetivo mismo.
Las empresas hoy buscan una transformación de sus objetivos alrededor de las tecnologías, no significa cambiar los objetivos sino utilizar las tecnologías como medios estratégicos para lograr un mejor servicio a la sociedad.
No es la tecnología lo importante sino las personas y su salud lo que tiene valor, de acuerdo con lo que Índigo Technologies busca con sus servicios.
Considero un logro importante a nivel país en el desarrollo de IA, con el fin de optimizar los recursos que se tienen y poder entregar algo más a la sociedad, aunque existen en otros países desarrollos similares con estos objetivos.
Links: