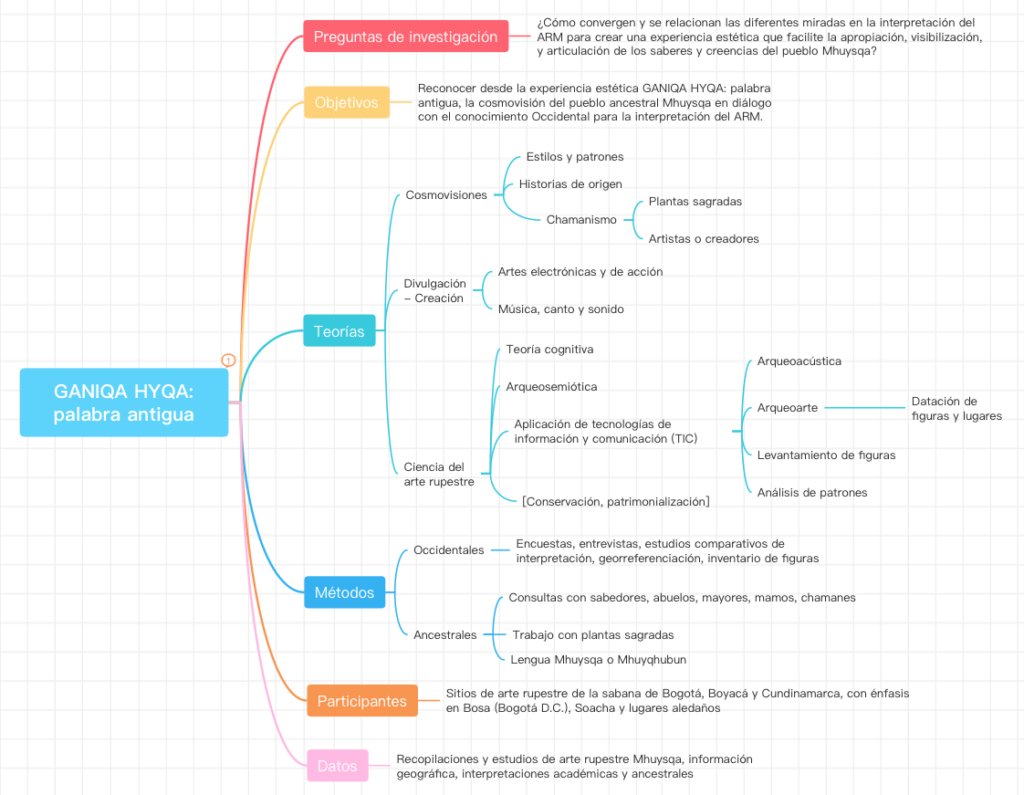
En mi calidad de miembro, o cabildante, del Cabildo Indígena Muisca de Bosa (CIMB) he planteado mi tesis de doctorado como investigación-creación (I+C), en torno al estudio de las pictografías y petroglifos del pueblo Mhuysqa, pueblo originario de los territorios de la meseta cundiboyacense y departamentos cercanos a ella.
La I+C utilizará metodologías y tecnologías Occidentales y ancestrales para su estudio y desarrollo. Es una apuesta intercultural de interpretación y puesta en escena, como una obra inmersiva que expondrá al visitante-espectador-usuario a vivir una experiencia estética del arte rupestre Mhuysqa.
El
autor en este artículo presenta un esquema que reflexiona sobre un enfoque
informático de la textometría relacionado con enfoques de la semántica
interpretativa.
Define
inicialmente la textometría o estadística textual que es la forma de la
lexicometría (Lebart et al.,2000), este análisis estadístico ha simplificado el
análisis de datos el cual se ha podido apoyar en herramientas tecnológicas para
su desarrollo. La propuesta de análisis
de los corpus ya digitalizados se plantea utilizando procedimientos de algún
orden definido y cálculos estadísticos, La lexicometría como herramienta
también ayuda a identificar unidades y patrones temáticos en los corpus, se
generan procedimientos cuantitativos, pero de interpretación cualitativa.
La
lingüística del corpus y la textometría, que se fundamentan en los corpus
digitales se centran en diferentes conceptos, la lingüística busca la
descripción de la lengua mientras la textometría se centra en el análisis de
textos y sus datos. Los análisis estadísticos se fundamentan en algunos
cálculos que finalmente llevan a las interpretaciones.
La
semántica interpretariva, es teoría linguistica la cual fue desarrollada por François
Rastier, (Rastier, 1987; Rastier, 2001), quien sugiere algunas herramientas
computacionales que ayudan a la interpretación de los textos.
Entrando
en el análisis de la textometría, el corpus se divide en unidades de acuerdo
con el tamaño de las palabras, aquí se genera una indexación que permite realizar
los procedimientos de búsqueda de una manera más eficiente, el corpus se
estructura como un texto; de acuerdo con los programas que se estén utilizando se
pueden definir las búsquedas necesarias que ayudan a establecer concurrencias y
patrones. La textometría permite el análisis y contextualización, global y local
y también algún ordenamiento del mismo texto, para el análisis estadístico más
eficiente se busca eliminar tanto las palabras poco frecuentes, como las
palabras muy frecuentas dentro del corpus
¿Se
puede relacionar un texto con “un saco de palabras”? los textos realmente no se
encuentran tan desestructurados como supone esta metáfora, lo cual implicaría
contar con cadenas de caracteres extraídas de un texto o de un corpus. Brunet
(2006b), plantea la descripción del corpus, no solamente basándose en las
palabras sino también usando elementos morfosintácticos, palabras descompuestas,
sucesiones de vocales y consonantes.
Los
cálculos que se realizan son cuantitativos, y la textometría utiliza los
modelos estadísticos, sin embargo, integra también una actividad cualitativa,
el procedimiento logra buenos resultados cuando se define claramente el problema
a resolver y se construye un corpus adecuado para la búsqueda. De acuerdo con Rastier,
(2001: VII.3.5), el análisis cualitativo le proporciona más significado a los
resultados cuantitativos.
El
autor nos presenta, algunas experiencias que muestran los descubrimientos
iniciales de la textometría realizados por la semántica interpretativa. Los
textos pueden presentar palabras claves que permiten generar interpretación, la
coocurrencia como otro efecto dentro de los textos, y el cálculo de estas
coocurrencias como un resultado textométrico.
En
la semántica interpretativa se han utilizado algunos programas informáticos
para el manejo de las coocurrencias, el más conocido y utilizado es el
Hyperbase de Brunet (2006a), que nos genera los cálculos de las coocurrencias. Otra
herramienta es el INaLF de Maucourt, en colaboración con Bourion, este programa
produce listas de los coocurrentes estadísticamente y también la frecuencia de ocurrencia;
como resultado presenta las líneas del contexto, pero en función de la
coocurrencia.
Bourion
propone como una siguiente funcionalidad el contar con resultados más seleccionados
además de las coocurrencias donde se podría ver la colaboración entre la
semántica interpretativa y la textometría, tratando de llegar a la localización
de un pasaje completo dentro del texto.
Las
experiencias planteadas por el autor permiten ver la textometría como una forma
de enfocar la investigación sobre un corpus en un esquema de semántica
interpretativa, para confirmar este planteamiento hay que contar con otros
elementos entre la semántica interpretativa y el método textométrico.
La
aplicación de la textometria hace posible una revisión de elementos
fundamentales incorporados a los marcos de la semántica interpretativa.
Otro
de los ejes constitutivos de este enfoque refiere a la caracterización de
textos y géneros textuales, que permite la distinción a partir de la
determinación de categorías temáticas, que permite una articulación de
elementos isotópicos y configuración de ramas comunes que permiten a su vez,
las relaciones de sub-corpus, establecidos a partid de elementos lexicales,
morfológicos y semióticos.
Algo que puntualiza Pincemin es la
determinación de lo global sobre lo local, lo cual evita restringir e análisis
a la mera observación de frases o elementos perdiendo su articulación,
orientando a la investigación a los tejidos estructurales del texto; es clave
no perder de vista que el análisis texto métrico exige la vuelta constante de
la mirada sobre el texto y no la reducción de sus partes. Con esta claridad, es posible acentuar la
mirada sobre elementos globales de clasificación como los géneros textuales,
que se vincularía a elementos de entrada como las descripciones
morfosintácticas y se amplía en revisiones infra textuales y supra
textuales. Para este procedimiento, se
sugiere integrar tres componentes: el dialéctico, el dialógico y el táctico.
Retomando
los elementos de la semántica interpretativa, se sitúa como central el interés
en-por el sentido, que pueden empezar a establecerse a partir de componentes
estructurales del sistema de clasificación de la lengua como la fonética, la
gramática, la morfología, la sintaxis, etc., pasando a explorar elementos como
el ritmo, la prosodia, las tipografías etc., haciendo vinculantes los elementos
de la lingüística y la semántica. Estos procedimientos requieren no perder de
vista el lugar central de los textos en todas las etapas del análisis.
En
este sentido, la unidad de análisis prioritaria es el texto, volcando el
estudio a todas sus dimensiones, lo cual en términos potenciales permite la
intervención sobre elementos micro (como las frases) pero generando conexiones
que nos reubiquen en el aspecto macro.
Ese enfoque permitirá descubrir sentidos que en análisis puramente
lingüísticos o lexicales quedarían restringidos. A su vez, el uso de herramientas como
Hyperbase, permite dirigirnos a la hipertextualidad, desplazamiento que brinda
orientaciones sobre las ocurrencias del contexto textual. Así, la contextualización se ubica como un
principio de análisis al momento de revisar los corpus establecidos; el
establecimiento de los lazos a partir de relaciones lexicales, sintácticos
etc., como las similitudes, permite el trazado de una cartografía de
tipologías. El autor especifica que desde la modelización pueden caracterizarse
contextos locales –a través de las coocurrencias y concordancias- , así como
globales, desde especificidades del análisis factorial de
correspondencias. Para ello se proponen
los principios de:
• Contextualidad: vinculo de pasajes o
signos de un mismo texto, donde los elementos de significación se evidencian
desde su reciprocidad.
• Intertextualidad: representa analogía
entre dos pasajes diferentes
• Architextualidad: este principio
establece que el texto situado en el corpus “recibe determinaciones semánticas
y modifica potencialmente el sentido de cada uno de los textos que lo
componen. De esta manera, todos los
textos incluidos en el corpus generan una lógica de sentido en las frecuencias globales.
El
abordaje del contexto amplia las dimensiones del significado y del contenido
mismo y permite, como los sugiere Rastier (2001), el matizaje de “formas que
destacan sobre un fondo”. Esto permite la conexión con el propósito de la
construcción del sentido que se genera en función del texto, que se ve
claramente incidida por la selección del corpus, pasando a su codificación y el
establecimiento de las correspondencias de datos desde los cuales se definen
las unidades, tipologías y otras categorizaciones que permiten definir el
cálculo apropiado que considera elementos cuantitativos, pero incorpora en su
base fundamental aspectos interpretativos (que se despliegan es experiencias
procedimentales como la hermenéutica de pasajes paralelos que recurre a la
comprensión de diversos pasajes en torno a un mismo tema).
Picemin
señala que la acción interpretativa puede definirse como una semántica
diferencial (como referencia de oposición a la semántica inferencial o
referencial) acentuando su materialidad en
la realidad lingüística, plateando así los contornos en los cuales se sitúa la
tarea textométrica, que enfoca la tipificación de unidades, estableciendo
frecuencias, separando temáticamente y desde tipologías concretas, que permite
concretar lo que se identifica y lo que se opone, las relaciones y los
contrastes. En esta tarea, si bien los
elementos estadísticos resultan cruciales, termina por acentual el valor
preponderante de lo cualitativo en la caracterización de estos sistemas de
sentido; ordenando criterios desde lo cuantitativo, el análisis se orienta
hacia acciones cualitativas que permiten establecer los matizajes, los puntos
medios, las correspondencias, las unidades que orientan la interpretación
siempre desde una vuelta al texto.
Reconocer
esta estructura, permite también referirnos a la unificación de la semántica interpretativa, por los
planos que articula desde las dinámicas interpretativas y diferenciales,
integrando aspectos de análisis que han pretendido abordarse de manera separada
o independiente (como el análisis pragmático o sintáctico), permitiendo de esta
manera que la textometria integre diversas dimensiones, como el estudio de
palabras, que se extienda, por ejemplo a las lexicalizaciones y de allí a las
coocurrencias, integrando a su vez elementos de la forma interior y de la forma
exterior que vincula los planos centrales de las formas semánticas y las formas
expresivas.
Estas
consideraciones son tenidas en cuenta en los diseños y posibilidades de las
herramientas informáticas y tecnológicas que posibilitan la medición
textométrica y desde allí, la modelización de los textos y los corpus
estructurados, en pro de avanzar el análisis sobre los múltiples niveles
lingüísticos, que se sigan proyectando sobre las unificaciones y grados de
diferencialidad (explicitados en las regularidades, las oposiciones, las
repeticiones, las singularidades, etc.), lo cual ha abierto el campo de la
textometria buscando enfatizar posibles funcionalidades que enriquezcan el
análisis .
Se
consolida así un proceso metodológico que permite el establecimiento de
correlaciones y elementos nucleares (o en palabras de Pincemin: moléculas
sémicas) claves en la conformación de los temas que consolidan la estructura
del texto. De esta manera se teje una
red que reconoce el valor de elementos lingüístico y se despliega hacia la
temática, la dialéctica, la dialógica y la táctica (componentes ya señalados
como claves de la descripción textual).
Desde la lógica de interfaces, la propuesta apunta a una integración que
pensaría en las funcionalidades, el examen y los encadenamientos, en un trabajo
multinivel.
De
esta manera, los aportes y consideraciones establecidos desde la semántica
interpretativa, permite ampliar los horizontes y la pertinencia del trabajo
texto métrico, como enfoque o diseño analítico que si bien está aún en
construcción, brinda herramientas y procedimientos que permiten la detección de
connivencias que hacen cruciales al texto, las dimensiones contextuales –o
contextualización-la intertextualidad y el establecimiento de corpus que en el
plano de la interpretación, permiten ver las dinámicas de producción de sentido
(en el eje del análisis semántico). Las
taxonomías y criterios explorados abogan también por el desarrollo de
herramientas informáticas, ampliando los márgenes de reflexión sobre la labor
semántica e interpretativa, desde dimensiones hermenéuticas, que, desde
operaciones cualitativas relevantes, pueden arrojar aspectos inéditos sobre las
bases materiales del texto.
Referencias
BRUNET,
Etienne (2006a). Hyperbase, logiciel documentaire et statistique pour la
création et l’exploitation de bases hypertextuelles. Manuel de référence.
Version 6.0 (mai 2006). Laboratoire Bases, Corpus et Langage, UFR Lettres,
Université de Nice.
LEBART, Ludovic; Salem, André et
Bécue, Mónica (2000). Análisis estadístico de textos, Lleida: Editorial
Milenio.
Pincemin, B. (2010). Semántica interpretativa y textometría. Tópicos del Seminario, 23, 15-55
RASTIER, François (1987). Sémantique interprétative, Presses Universitaires
de France. Traducción de Eduardo Molina y Vedia: Semántica interpretativa,
México: Siglo XXI, 2005.
RASTIER, François (2001). Arts et sciences du texte, Presses Universitaires
de France. Traducción de Enrique Ballón Aguirre: Artes y ciencias del texto [en
prensa].
Fairchlough (1989), en este capítulo
presenta cuatro temas fundamentales relacionados con el discurso los cuales se
resumen en el lenguaje y el discurso, el discurso y las órdenes de discurso,
clase y poder en sociedades capitalistas, y dialéctica de estructuras y
prácticas. Estos temas son
posteriormente desarrollados en oros capítulos en más detalle.
Iniciando con el lenguaje y
el discurso a través de un ejemplo de conversación nos muestra como las
condiciones sociales ayudan a determinar las propiedades mismas del discurso,
así mismo es importante tener cuidado en la interpretación de los textos y la
producción de estos y como los procesos están inmersos en la sociedad misma.
Lenguaje y discurso: el lenguaje
determinado como una práctica social por las diferentes estructuras sociales, pero
el termino lenguaje tiene varios sentidos de uso, incluidos la lengua, “langue”
y la palabra “parole”, donde Saussure presenta la lengua como un sistema previo
al uso del lenguaje actual el cual se considera el mismo para la comunidad, y
todos tienen el mismo acceso al lenguaje, mientras la palabra “parole” se
convierte en individual.
El discurso como práctica
social: el lenguaje es parte de la sociedad y los fenómenos lingüísticos son
fenómenos sociales., es un proceso social y adicionalmente es condicionado por
la sociedad.
Volviendo al lenguaje como
un proceso social, y buscando diferenciar el discurso del texto, el texto es un
producto más que un proceso, mientras que el discurso es un proceso de
relacionamiento social del cual el texto es solamente una parte. Este proceso
incluye la producción del texto y la interpretación de este. El análisis del
texto es una parte de análisis del discurso, el cual incluye proceso de
producción e interpretación, por lo tanto, el discurso incluye condiciones sociales
que se pueden especificar como condiciones sociales de producción e
interpretación.
El lenguaje visto como
práctica social y como discurso, parte del compromiso de las personas es no
solamente analizar los textos, o su producción e interpretación, sino el
análisis de la relación entre texto, proceso y condición social.
El lenguaje visual y verbal
también es un elemento importante en los discursos, cuando se tienen textos
hablado, y entran otros elementos a ser parte interpretativa del discurso.
El discurso y órdenes del
discurso: para Michael Foucault, las órdenes del discurso son los conjuntos o
redes interdependientes, lo que es una ideología particular. Se presenta una
diferenciación entre orden social y orden del discurso, vistos como practicas
sociales o de discurso. Las órdenes sociales difieren en los tipos de prácticas
que relacionan y las órdenes de discurso difieren de acuerdo con los tipos de
discurso que relacionan.
Clase
y poder en sociedades capitalistas: las condiciones sociales del discurso
pueden ser diferentes a nivel institucional, dadas las relaciones de poder a
nivel de instituciones y regidas por esquemas capitalistas, por ejemplo,
instituciones regidas por esquemas de producción con fines de lucro comerciales
o de utilización inmediata. Se presentan en las diferentes sociedades,
relaciones de poder, relaciones de clases y luchas sociales, de grupos étnicos,
hombres y mujeres.
En
el análisis de la sociedad y análisis del discurso nos presenta el autor
algunas relaciones para poder determinar cuáles pueden ser revisadas en las
sociedades capitalistas y sus características de órdenes del discurso.
Dialéctica
de estructuras y prácticas: la relación entre las estructuras sociales y el
discurso tiene argumentaciones que pueden ser dialogadas. El discurso
contribuye a los cambios sociales, así como a su continuidad.
Referencias
Fairchlough, N. (1989) Language and power. Longman. (Capitulo
2: Discourse as social practice)
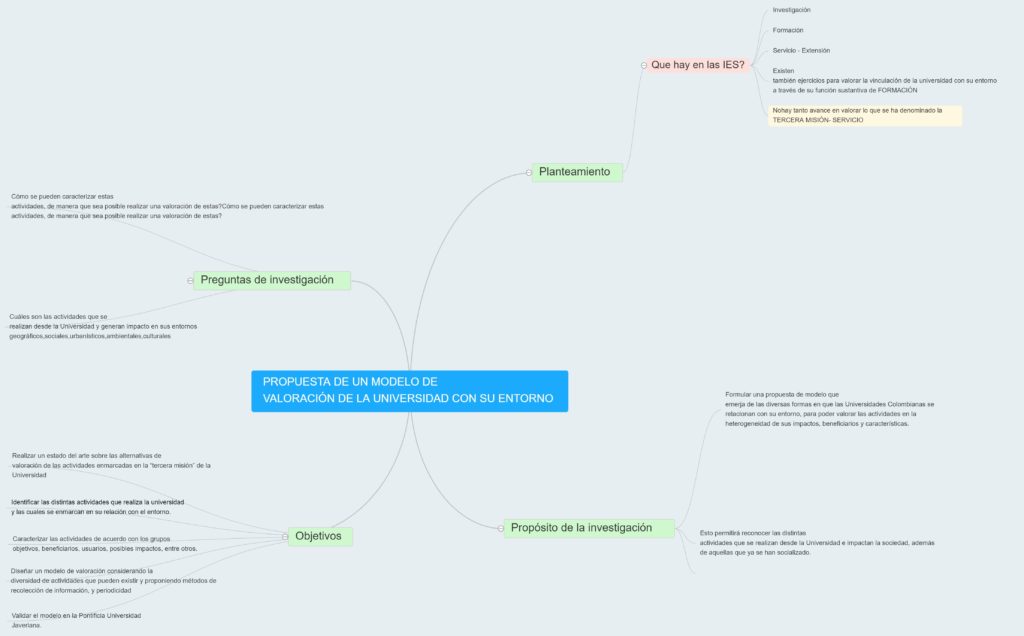
En Colombia, las (IES) – Instituciones de Educación Superior cumplen con varios objetivos misionales que trascienden la formación de profesionales, por ejemplo, la Javeriana, en su Planeación Universitaria 2016-2021, establece como objetivos misionales el ejercicio de la docencia, la investigación y el servicio con excelencia, como universidad integrada a un país de regiones, con perspectiva global e interdisciplinar.
En este sentido hay contribuciones teóricas que han resaltado los cambios en las maneras tradicionales de producir conocimientos y la forma en que estos pueden impactar la sociedad, particularmente a través de la innovación. El argentino Jorge Alberto Sábato propone en la década de los 60, una estructura triangular entre la industria, la infraestructura científica y tecnológica y el estado como modelo para el desarrollo de la política de ciencia y tecnología en América Latina (Sábato, Botana 1968). El sistema de innovación fue propuesto como un modelo funcional que motiva la innovación como el resultado de interacciones entre distintos tipos de actores (Lundvall, 1993), por su lado, el modelo de la triple hélice (Leydesdorff y Etzkowitz, 1993) resalta el papel de las organizaciones formales, y las relaciones entre los actores para que el conocimiento y la información incidan en el desarrollo económico y social de los países.
Las anteriores contribuciones ayudan a modelar la relación de la universidad con su entorno desde sus funciones de formación y de investigación y producción de conocimiento, pero que sucede con la tercera misión de la IES, donde ésta se enfoca en el servicio y en la contribución social al país.
El objetivo principal de mi investigación se focaliza en esa tercera misión de las IES, y en particular de la Pontificia Universidad javeriana, con el fin de formular una propuesta de modelo que emerja de las diversas formas en que las universidades colombianas se relacionan con su entorno, que permita valorar las actividades en la heterogeneidad de sus impactos, beneficiarios y características.
Esto permitirá reconocer las distintas actividades que se realizan desde la universidad e impactan la sociedad, además de aquellas que ya se han popularizado y socializado.
En este proyecto se pretende realizar una pequeña investigación preliminar para consecución de datos utilizando herramientas avanzadas para este fin. Los datos se obtienen de Media Cloud o de la red social Twitter; para el caso de mi investigación relacionada con universidades, sus funciones, misiones, y relaciones con su entorno, la idea es buscar información a través de Twitter que permita realizar algún análisis relacionado con el propósito de la investigación y poder generar algunas conclusiones.
El éxito de la investigación estará siempre en los datos, en la naturaleza de estos, en los esquemas de recolección y finalmente en los métodos de análisis que se escojan. Walliman (2011), en su libro nos presenta las formas en que encontramos los datos, estos se encuentran en dos formas, datos primarios, y datos secundarios. Los primeros son directos de la observación y los segundos llevan interpretación. Existen cuatro tipos de datos primarios de acuerdo con su esquema de recolección, por medida, por observación, por interrogación y por participación. Los datos primarios son los más confiables. Los datos secundarios, dependen de las fuentes para su confiabilidad.
Los datos base para este proyecto son datos primarios tomados a partir de participación en la red twitter con base en la creación de un .bin. A partir de estos primarios va una interpretación para generar un análisis lo cual los convierte en datos secundarios. En este caso se toman datos de una semana y mas adelante explico con cuál herramienta se recolectan los datos.
Adicionalmente está el método de análisis de los datos, Hernández Sampieri (2010), plantea los métodos de análisis de los datos, métodos cuantitativos y métodos cualitativos. Según Sampieri los fenómenos actuales de las ciencias son tan complejos que requieren métodos mixtos, cualitativos y cuantitativos.
Para este proyecto se utiliza inicialmente método cualitativo por el tipo de herramientas y de muestra que se obtiene. Los datos provienen de redes sociales, son datos no estructurados, necesitan interpretación. Posteriormente el análisis puede llegar a dar unos elementos cuantitativos producto de este, estos datos se refieren a conteo de palabras, de mensajes, usuarios que claramente son cuantitativos.
Como herramientas para este proyecto se utiliza TCAT (Twitter Capture and Analysis Toolset), que es un conjunto de herramientas para recuperar y recoger tweets de Twitter y analizarlos de varias formas. TCAT fueron desarrolladas por investigadores University of Amsterdam con el propósito de apoyar el avance de los métodos digitales de investigación. (Guia de TCAT).
Con la versión que cuenta la Javeriana DMI-TCAT instalada en servidores de Caoba y el laboratorio de Big Data (facultad de Comunicación + Ingeniería), para uso académico de estudiantes y profesores, se creó la base para generar los datos para este proyecto. (Guia de TCAT).
Para el análisis se tomó desde Admin, creando un “bin” y algunas palabras seleccionadas, con los datos iniciales se realizan algunos “queries” y exclusión de algunas palabras para refinar un poco las búsquedas.
Los datos recolectados se descargan en archivos CSV para su posterior análisis. Se utilizaron otras herramientas externas a TCAT para el análisis y las estadísticas, Open Refine, Excel y para el análisis de redes se hizo con Gephi.
Inicialmente se generan un número de datos considerable que pueden ser la muestra, pero con un análisis rápido se ven datos que no aportarían al objetivo; por lo tanto, se realizan unos filtros sobre los tweets que me permitan tener un data set más afinado.
Se realizan filtros por país, incluyendo solo Colombia y posteriormente excluyendo Cuba para llegar a datos que estén más de acuerdo con el objetivo.
Se crea inicialmente un “bin”, desde Admin, utilizando TCAT de la Universidad Javeriana, y este “bin” se crea con las siguientes condiciones:
Fecha inicio: 10 02 2020
Fecha fin: 17 02 2020
El “bin” se crea con algunas palabras claves que ayuden a recibir tweets que sean de utilidad para el proyecto de investigación. Estas palabras fueron:
Universidades
Misión
Extensión.
Para estas palabras claves se presentaron 71.000 tweets, como base de la recolección planteada.
Una primera revisión general de los datos muestra datos de universidades en el mundo por lo cual se hace un filtro solamente para Colombia. Este filtro deja un conjunto de 2.220 datos. Iniciando algún tipo de análisis se observan muchos datos de Cuba con lo cual se refina la búsqueda a excluir a Cuba.
Por lo tanto, la muestra para el análisis se determina como:
Palabras claves: universidades/misión/extensión
Query: Colombia
Excluir: Cuba
Total de tweets: 1.354
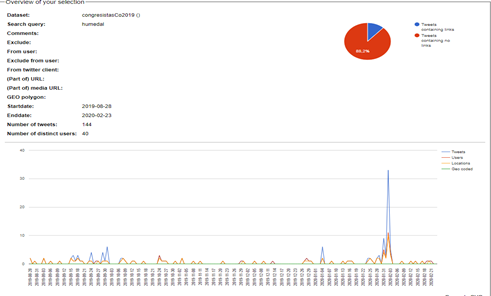
Las siguientes Gráfica 1a y Grafica 1b muestran resultados de las búsquedas ya filtradas.
Grafica 1a – resultados de TCAT
Grafica 1b – resultados de TCAT
3.1 Estadísticas:
El conjunto de estadísticas de datos obtenidos se muestra en la siguiente gráfica:
Grafica 2 – estadísticas
Las estadísticas muestran, lo siguiente:
Los 1354 tweets se concentran en la mitad del período, adicionalmente el número de re-tweets es de 963 que equivale al 71%.
El número de tweets con links, hashtags, o menciones no es considerable en la muestra y no llega al 1%.
El número de replies es de 226 que corresponde al 16% de la muestra.
Por el contrario, el número de tweets con menciones es de 1249 que corresponde al 92%.
Se extraen como datos para análisis:
Export de tweets
Hashtags
Id de usuario
Número de twwets
Export de la red para ser llevada a Gephi
Con esta base se obtiene lo siguiente datos, que se ven reflejados en las gráficas de BATABASE.IO, y las tablas correspondientes.
De acuerdo con el planteamiento de los datos recolectados se puede generar algún análisis.
Realizando alguna mirada sobre los tweets producto de esta búsqueda, se observa que la mayoría se refieren a situaciones de orden público que se presentó durante la semana de la investigación. Por lo tanto, los resultados son de alguna manera inesperados frente a lo que se pensaba.
En la Gráfica 3a – Fechas de recolección – feb 10 – feb 16, User-id – usuarios que realizaron tweets
Grafica 3a -usuarios y tweetts
Gráfica 3b – Fechas de recolección – feb 10 – feb 16, User-id – usuarios que realizaron tweets
Únicamente 13 usuarios realizan 3 tweets, un usuario 4 tweets y un usuario 5 tweets.
No se muestra en la tabla, pero 59 usuarios realizan 2 tweets y el resto uno o ninguno.
El número de re-tweets de estos usuarios no es representativo, llama la atención el número de menciones del usuario “sergioaraujoc” que llega a 248. Este usuario con 3 tweets reúne una gran cantidad de menciones que se observan posteriormente en los diagramas de red.
Dentro del análisis de usuarios cabe resaltar este usuario “sergioaraujoc” pues presenta en el data set,
En la Gráfica 4 – análisis de intervalo de tiempo, se muestra el comportamiento del número de registros por fechas de la muestra, y se ve una clara disminución a partir del 13 de febrero que puede deberse a la misma situación de orden, ya mencionada. Esta misma situación se aprecia en la gráfica de estadísticas de este data set.
En la Gráfica 5, se muestra que el número de tweets como ya se mencionó, el máximo es 5, teniendo una tendencia el 1 y el 0, sobresale el usuario “sergioaraujoc” quien con 3 tweets reúne una gran cantidad de menciones que se observan posteriormente en los diagramas de red. Los usuarios que se pueden identificar de universidades, en este data set tienen pocos tweets y adicionalmente no aparecen todas.
En la Gráfica 6a, se presenta la frecuencia de “url”, la cual oscila entre 1 y 7 y estos se refieren básicamente a los “url´s” de la Gráfica 6b, los cuáles muestran claramente que se refieren a noticias de orden público, incluso uno de estos url se refiere a un tema de universidades latinoamericanas pero referente a un tema de denuncia judicial. El “url” de mayor frecuencia – 7, se refiere a laguna situación del esmad, que ayuda a concluir la situación de orden.
Para el análisis de los tweets se tiene una vista de frecuencia de palabras donde se puede analizar algo el tipo de lenguaje utilizado
En la Grafica 7a, podemos observar la frecuencia de palabras en el data set base de la recolección, en su representación gráfica por tamaño de ocurrencia de palabras.
En una mirada general resaltan palabras como “universidades”, “Colombia”, “estado”, “pueden”, y algunos conectores como “para” “que” y verbos como “son” “pueden” “dejar”, que tendrían algún valor para mi objetivo, pero sus complementos son palabras como “armas” “violar” “eln” lo cual nos lleva a temas de orden público.
Gráfica 7a – conteo palabras y su representación
En la Gráfica 7b de DataBasic, se aprecia el correspondiente conteo de palabras como “universidades” – 1428, “Colombia” – 450, “policía Colombia” – 439, “estado” – 434, los bigrams y trigrams de esta gráfica nos muestran resultados como “la autonomía universitaria”, “envuelven la policía Colombia”, “la policía Colombia”, que reflejan situaciones de orden público.
Utilizando la estadística de menciones, se tienen 590 menciones y 969 re-tweets. En esta vista se tienen 373 te-tweets del usuario “sergioaraujoc”, el usuario “contagioradio 1” tiene 98 re-tweets. El usuario “WRadioColombia con 255 retweets.
Algunas menciones de 40 para “policía nacional”, “el colombiano” con 30 y aparece un usuario “egarciarujes” con 28 re-tweets y el usuario “CristinaRevolt” con 42. Estos son los valores más representativos lo cual lleva a una dispersión aún mayor de la red.
En la Gráfica 8a , se pueden apreciar los usuarios más representativos del data set, por número de menciones y/o re-tweets. Se puede observar la concentración en unos pocos usuarios.
Gráfica 8a – usuarios más representativos
Los usuarios de las universidades también tienen su presencia en este data set, 68 menciones.
Gráfica 8b – usuarios de universidades
Sin embargo, su representación es muy baja frente a otros usuarios, teniendo en esta gráfica anterior, Gráfica 8b, todos los usuarios de universidades. Sin embargo, no hay tweets de estos usuarios
El cuento de que la autonomía universitaria da para que universidades sean un bastión y guarida del terrorismo, que me lo envuelvan. La @PoliciaColombia y las @FuerzasMilCol no pueden tener territorios vedados. Son las armas de la democracia. La capacidad cohercitiva del estado
1228431452393680901
1581715856
2020-02-14 21:30:56
sergioaraujoc
Ese cuento de que la autonomía universitaria da para que las universidades sean bastión y guarida del terrorismo, que me lo envuelvan. La @PoliciaColombia y las @FuerzasMilCol no pueden tener territorios vedados. Son las armas de la democracia. La capacidad coercitiva del estado
Estos dos tweets del usuario “sergioaraujoc”, son los que concentran las RT- 373, indicadas anteriormente y por lo tanto concentran la red. Claramente se refiere a algún comentario que genera situaciones de respuesta.
1229206119874269186
1581900551
2020-02-17 0:49:11
RivasRegalOne
Que buena Noticia, las mayoría de Universidades Colombianas inaugurarán sus Regionales en Florencia, en Puerto Carreño, en Puerto Inírida, en Mocoa, en Mitú, en Yopal y en San José del Guaviare. Bien.
1227967206891433984
1581605171
2020-02-13 14:46:11
RankiaColombia
Mejores Universidades Virtuales en Colombia https://t.co/jnO0h5BeMz
1228027328078471169
1581619505
2020-02-13 18:45:05
foris
Experiencias de Universidades en Colombia con respecto al éxito estudiantil. https://t.co/QHkQuLs8qu #Colombia #StudentSuccess #Retención #Foris
Estos tres tweets mencionan situaciones importantes de las universidades en Colombia, pero las menciones y seguidores o RT son mínimos, y no se ven en las redes.
1228803076804534272
1581804458
2020-02-15 22:07:38
Daniela_A_Gallo
El caso de TODAS las universidades de Colombia, si quienes estudiamos somos la minoría y no tenemos acceso tan evidente y sencillo a atención mental, ¿cómo será para el resto de los jóvenes?
Este tweet puede ser una solicitud a las universidades por una necesidad de atención mental, lo miso son tweets que no se ven representados en la red.
Docentes de universidades públicas denunciaron un montaje judicial que se estaría creando en su contra por promover pensamiento crítico en Colombia https://t.co/eNTWpb0WTo https://t.co/vOgHFa6J1m
1228304131254710272
1581685500
2020-02-14 13:05:00
Contagioradio1
“No vamos a dejar que acallen al pensamiento crítico en Colombia” docentes de universidades públicas denunciaron que serían víctimas de un montaje judicial https://t.co/eNTWpbixKW
1227565886451671040
1581509489
2020-02-12 12:11:29
carrique6181
¿Por qué es tan polémica la propuesta de enviar fuerza pública a las universidades? https://t.co/hfLjxrYzBK vía @elcolombiano
1227686078200590338
1581538145
2020-02-12 20:09:05
Daniel_VasquezT
En Colombia las universidades públicas se volvieron un santuario para los crimínales. La Policía no puede actuar. En Medellín casi impactan un bus con un explosivo https://t.co/fZvp5QzE9N
1227952619341127680
1581601693
2020-02-13 13:48:13
JESUSLADEUTH
Quintero estrenó protocolo de reacción ante explosivos en las universidades via @elcolombiano móvil https://t.co/nd547OLdbO
Claramente estos tweets, son situaciones de orden público y de quejas hacia las universidades públicas. De estos tweets anteriores, el usuario “contagioradio 1” generó 98 RT con este twwet, algo que representa un poco más en la gráfica.
Para centralidad de la red, e identificación de comunidades/clusters, se utiliza la modularidad como medida de la estructura de la red. Sirve para mirar el agrupamiento de los nodos. Se utilizó una Resolución de 5.0 con una modularidad resultante de 0.769. Grafica 9.
Sobe los algoritmos utilizados en el análisis de red, Page rank, para la medición de la importancia de cada nodo en la red, se asignó una probabilidad de 1.0 y un Epsilon de 0.001. Gráfica 10.
Sobre el data set se utilizó algoritmo Page-rank, para centralidad de la red, así mismo y para la identificación de comunidades/clusters, se afinó la Modularidad. Para la distribución de la red se utilizó el algoritmo Force atlas 2. Gráfica 13, muestra los parámetros de este algoritmo.
Para el posicionamiento de los nodos con respecto a los otros se utilizó el algoritmo Force atlas 2, se aplica una reducción de la dispersión y una gravedad para acercarlos.
Parámetros utilizados:
En las siguientes graficas se muestran los grafos y los respectivos parámetros asignados en cada unos de los algoritmos descritos anteriormente.
Modularity Report
Parameters:
Randomize: On Use edge weights: On Resolution: 5.0
Results:
Modularity: 0.769 Modularity with resolution: 4.647 Number of Communities: 74
Gráfica 9 – Modularidad
PageRank Report
Parameters:
Epsilon = 0.001 Probability = 1.0
Results:
Gráfica 10 – Page rank
Con base en algunas gráficas de red en Gephi, que permiten generar análisis claramente la red es bastante dispersa, en su mayoría. Se presenta una concentración importante la cual se observa en la Gráfica 11, alrededor del usuario “sergioaraujoc”, quien tiene registrados 3 tweets y a partir de estos genera esta gran cantidad de menciones.
Gráfica 11 – Grafica de red teniendo en cuenta los 1354 resultados
En la Gráfica 12a y 12b,, se observa una pequeña concentración (tono fucsia) que se refiere a los usuarios de las universidades que aparecen en la muestra. Se concentran en un punto, pero sigue siendo disperso el resto de los usuarios.
Grafica 12a – muestra de una concentración en fucsia que se refiere a las universidades
Grafica 12b – detalle de la concentración fucsia que son las universidades
La dispersión de la red es más clara en la Gráfica 13
Gráfica 13 – muestra la dispersión de los datos
El análisis general, realmente no aporta a la investigación, puesto que la intención de obtener tweets de las universidades o de lo que se pide a las universidades no se logró con esta muestra. Básicamente se concentró la muestra en algunos tweets generados por una situación de orden público que no era realmente el propósito. Pero se lograron algunos análisis sobre el data set generado.
De acuerdo con Rogers (2013), es importante tener claro cómo conseguir la data y como analizar los objetos digitales, hyperlinks, tags, search engine results, archived websites, social networking sites profiles, Wikipedia edits.
Por lo tanto, como conclusión al ejercicio, se deben tener en cuenta varios elementos precisos al momento de tomar las muestras de datos que se van a requerir. Para el caso de recolección de datos en redes sociales es importante tener conocimiento de las formas y esquemas para esta recolección, dado que es el insumo principal para el análisis.
Las investigaciones tienen algunas limitaciones con los datos tomados de redes sociales, puesto estos pueden ser inestables y no siempre ser permanentes; adicionalmente las herramientas pueden restringir los textos, y los datos se toman en determinados intervalos de tiempo que pueden también restringir la investigación. Rogers (2013).
Cómo conseguir la data y como analizarla, y de donde tomarla, son temas importantes a tener en cuenta para estas investigaciones. También hay que considerar que los datos de las redes son datos no estructurados y adicionalmente llevan la interpretación de quien está enviando el mensaje, lo cual significa que son datos cualitativos, e implica un mayor análisis de su contenido para llegar a mejores conclusiones.
Surgen algunas preguntas cuando nos enfrentamos a los medios sociales y a la recolección de datos a través de estas, ¿cómo abordar la investigación en internet?, ¿Cómo enfocar los medios?, ¿Que herramientas usar?, ¿Como definir de acuerdo con la investigación las preguntas anteriores?
De acuerdo con el objetivo planteado en este documento, no se logró recolectar datos que ayuden a revisar la relación de las universidades, con su entorno en todas las funciones que éstas desempeñan.
Para mí trabajo fue importante aprender a recolectar datos de redes sociales que me permitan posteriormente analizar y generar conclusiones.
Pienso que debo investigar más como las universidades se pronuncian a través de Twitter para lograr recolectar la información que realmente me pueda servir. Para esta investigación, sería importante contar con usuarios de las universidades, también a través de los portales y la forma en que las universidades se manifiestan en las redes sociales, en twitter principalmente.
Como un ejercicio siguiente me gustaría crear un “bin” con temas más precisos y búsquedas más alineadas con el propósito de mi investigación. Para este fin he pensado en algunas preguntas que me podrían servir para establecer resultados más afines a mi proyecto.
Las posibles preguntas que tengo serían:
¿Cuál ha sido la historia de las relaciones de la comunidad con otros actores a través de twitter? esta comunidad pueden ser las universidades o más precisamente la Javeriana.
¿Qué se le pide a la Javerana a través de twitter?
¿Qué dice la Javeriana a través de twitter?
¿Con quién y cómo se relaciona la Javeriana a través de twitter?
¿Cómo valorar la relación universidad entorno a través de twitter?
Y para finalizar pienso que es importante continuar aprendiendo de estas herramientas robustas que pueden permitirme generar análisis interesantes e importantes para mi investigación.
Fue una excelente experiencia frente a otro tipo de datos y los resultados que se pueden llegar a obtener.
Hernández Sampieri, R., Fernández Collado, C., Baptista Lucio, P. (2010). (5a Edición). “Capitulo 17: Los métodos mixtos.”
Leydesdorff, L. y Etzkowitz, H. (1996). Emergence of a Triple Helix of University- Industry-Government Relations. Science and Public Policy, 23(5), 279-286.
Rogers, R. (2013). “Introduction: Situating Digital Methods” y “The End of the Virtual: Digital Methods.” Digital Methods. Cambridge, MA: The MIT Press. pp 1-38.
Sábato, J. A. y Botana, N. (1968). La ciencia y la tecnología en el desarrollo futuro de América Latina. Revista de la Integración, (3), 11.
Walliman, N. (2011). “Ch. 6. The nature of data,” “Ch.7. Collecting and analyzing secondary data”, “Ch.8. Collecting primary data.” Research methods: The basics. London: Routledge. pp. 65-127.
La siguiente investigación tiene como fin analizar si existen, y de ser así, las formas de interacción y controversias de los congresistas hacia los humedales. De esta forma, se pretende esgrimir el lenguaje dentro del conocimiento y preocupación de estos sujetos frente a dichos espejos de agua mediante la red social twitter.
Las problemáticas que sufren los humedales en el país, no suelen ser de gran reconocimiento nacional. Las políticas, decretos, resoluciones, acuerdos y demás documentos legales, en la mayoría de los casos, no son compartidas con el general de la población, sin embargo, en la última década se ha vuelto necesario, casi que imperativamente, buscar información relevante, con fin de comprobación desde las redes sociales.
Para este caso específico, se toma la red Twitter con el fin de encontrar las interacciones tejidas alrededor de la palabra humedales, encontrando así, las formas de denuncia, reconocimiento, propuestas y demás, en torno a este tema específico. En cuanto a la realización de la investigación, fue necesario buscar en el bin “congresistas” desde el TCAT creado por un grupo especializado de la Universidad Javeriana. En este grupo se comparte información variada del país, encontrado puntos de tensiones, temas de base, reclamaciones y demás recurrencias e información pertinente al tema de investigación. Por lo anterior, es posible preguntarnos
¿Cuál es el flujo de interacción discursivo desde el ámbito político, expresado en el bin “congresistas” analizado desde la red social twitter desde el 28 de agosto de 2019, hasta el 14 de febrero de 2020? ¿Qué se comunica desde allí?
Métodos y herramientas
Se realiza la búsqueda en TCAT, instalado en la sala Big data de la Universidad Javeriana, en primer momento se revisa el bin creado el 17 de febrero llamado “humedales”, el cual no arroja los elementos suficientes para poder realizar un análisis sólido. Por lo anterior, se filtra la búsqueda en el bin “congresistas” intentando observar y analizar la información; allí se encuentran 141 menciones en tweets, cuya recurrencia y foco es la palabra humedales.
Por otro lado, se utiliza la herramienta Gephi con el fin de analizar y diagramar la búsqueda en red, generando la graficación que explica el análisis. De esta forma se hace más simpe la observación /percepción de las formas y flujo de información, respecto a los tweets.
Datos
Bin: Congresistas Query: Humedales
Fecha: Agosto 28/2019 – Febrero 14/2020 Tweets: 141
Actores: 159
Tabla 1. TCAT reconocimiento de información
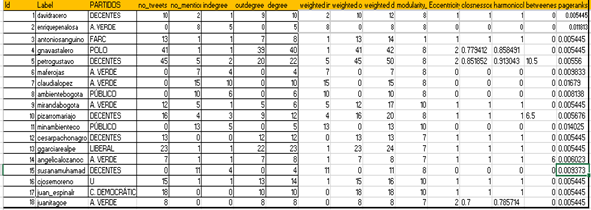
ANÁLISIS DESDE LOS NODOS
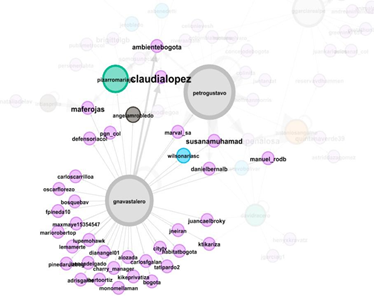
Muestra el número de interacciones recurrentes que se puede observar. Se muestran los sujetos que tienen más de 6 interacciones, bien sea como tweets, o como menciones. Cabe aclarar, que no se corresponden las dos anteriores, ya que, como ejemplo, el caso de Claudia López, no ha compartido ningún tweet, pero sus grados de entrada son corresponsables a las interacciones que tiene este usuario.
Tabla 2. Lista de interacciones recurrentes
Por otro lado, se observan las interacciones como filtraciones de partido, lo que denota una fuerte participación de partidos políticos de izquierda y centro izquierda (94%), frente a la participación de partidos políticos de derecha (6%).
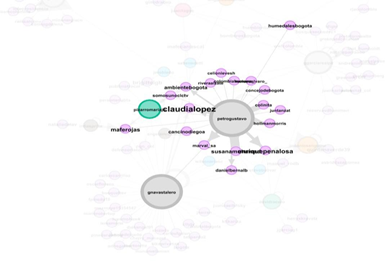
La graficación correspondiente al análisis numérico de la tabla 1, se corresponde a la tabla siguiente:
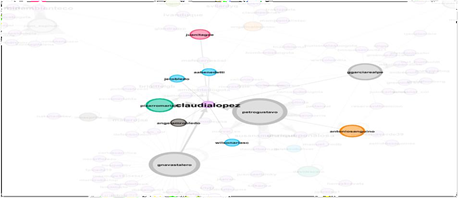
La gráfica anterior muestra las interrelaciones que se tejen respecto a la palabra humedales en el grupo de congresistas. Acá se atenúan los flujos de interacción entre los mismos, dejando ver en la gráfica las principales recurrencias y nodos que se forman. Los nodos que más interacción poseen, suelen ser realizados por los mismos congresistas, sin embargo, existen casos particulares, cuyo rasgo se caracteriza por la dirección pública, este crea el nodo sin realización obligatoria de tweet, como es el caso de Claudia López, Enrique Peñalosa, Iván Duque (0 tweets – reconocimiento por grados de salida).
Ejemplo:
Tabla 4. Flujo de tweets Claudia López
A continuación se muestran los nodos con mayor influencia y sus formas de interacción
Tabla 5. Nodo: Germán Navas Talero
Gnavastalero
POLO
41
1
1
39
40
1
41
42
8
2
0.779412
0.858491
0
0.005445
Este nodo muestra da una muestra clara de los grados de salida pertenecientes al usuario. Estos se pueden definir por el número de tweets que ha realizado en este lapso de tiempo, cuya replica ha sido mínima, no equiparable con la forma de producción de tweets. Sus tweets hacen menciones a denuncias e información afincada en los humedales de Bogotá. Se manifiesta constantemente con noticias que ponen en riesgo y a su vez reflexionan sobre los humedales.
Tabla 6. Nodo: Gustavo Petro
petrogustavo
DECENTE
45
5
2
20
22
5
45
50
8
2
0.851852
0.913043
10.5
0.00556
Al igual que Navas Talero, focaliza su fuerza de interacción desde el lugar de la realización de tweets. El caso de Petro, se encuentra mediado por dos categorías de construcción de tweets, la primera desde la denuncia, que lo ubica en el lugar de hablar sobre hechos y nombres concretos que afectan la salvaguarda de algunos humedales como el Burro; y la segunda desde un tinte de campaña política que pretende mostrar acciones concretas en los lugares para que en un segundo pano sean reconocidas y ubicadas con nombre propio.
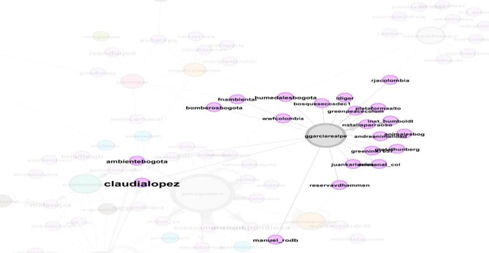
Tabla 7. Nodo García Realpe
ggarciarealpe
23
1
1
22
23
1
23
24
7
1
1
1
0
0.005445
El caso de @garciarealpe muestra el foco de sus interacciones representados en una denuncia abierta del incendio que hubo en el Humedal Tibanica en Octubre de 2019, realiza llamados a diversas ascoaiciones, congresistas, activistas y demás a volcar la mirada hacia el probelma en cuestión. Es posicionado en la escala de nodo recurrente por la generación de enlaces realizados.
Los nodos siguientes correspondes a dos entidades gubernamentales
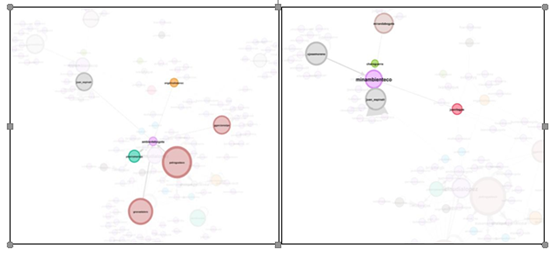
Tabla 8. SECRETARIA DE AMBIENTE Tabla 9. MINISTERIO DE MEDIO AMBIENTE
En las gráficas anteriores se infiiere la responsabilidad atribuida a las dos entidades puesto que sus formas de interacción son casi nulas en el entramado del grupo; sin embargo mantienen agencia frente a las responsabilidades políticas, públicas, sociales y medio ambientales alrededor de los humedales. Para este caso, el número de tweets no presenta relevancia en la información que muestran, pero si se hace interesante buscar la forma como se nombran desde figuras políticas
ANÁLISIS DESDE LA INFORMACIÓN
CATEGORÍA 1: Denuncias, respecto a humedales
Los tweets señalados con rojo, presentan una relevancia hacia la denuncia de acciones, tanto individuales, como colectivas públicas, en contra de los humedales. Una de las más atenuantes es la denuncia a la afectación del humedal El Burro, la cual es acompañada en diversos tweets, y por diferentes usuarios. Este punto específico, es el más recurrente, ya que abre nuevas enunciaciones sobre el mismo humedal, entre ellas, el convenio firmado por Enrique Peñalosa que permite la entrada de la constructora Marval a los linderos del mismo humedal, afectando el espejo de agua y las especies que lo habitan; el no reconocimiento de este humedal, el cual fue ingresado en la lista de humedales distritales en la Bogotá Humana y desvinculado bajo la acción de desconocimiento por decreto por el anterior alcalde, Enrique Peñalosa; y la falta de empoderamiento de la alcaldesa por el tema del humedal.
Las denuncias respecto a los humedales parten de tres nodos importantes que son Gustavo Petro, Germán Navas Talero y María José Pizarro; estos tres se manifiestan desde voces diferentes del agua que contienen los humedales Tibabuyes, El Burro, Juan Amarillo desde un lugar de enunciación denunciante que nombra, específicamente, en la mayoría de los casos, las responsabilidades estatales, sobre el deterioro, las obras
adjudicadas que contemplan la transformación del suelo de los mismos y la amenaza constante al espejo hídrico y la avifauna que lo habita.
CATEGORÍA 2: Información general
Esta categoría muestra información de interés acerca de los humedales, su principal nicho se encuentra en el mes de enero en conmemoración del día de los humedales, cuya fecha corresponde al 2 de febrero. Se puede ver información clara de la importancia y relevancia de los humedales en el planeta y se enuncia las formas de manejo ambiental que se pueden dar para su salvaguarda. En esta categoría toman especial fuerza los tweets de Juan Espinal y Miranda Bogotá.
CATEGORÍA 3: Campañas políticas
La categoría de campañas políticas se encuentra dispersa en la base de datos, esta muestra pocas interacciones recurrentes, aunque maneja diversa información de acciones en salvaguarda de los humedales que los candidatos han realizado. Un ejemplo claro lo muestra Antonio Sanguino, quien aprueba las formas de acercamiento de @QuintanaVerde y @AstridDazaGomez a los barrios de la localidad de Kennedy, consiguiendo desde la red social, mantener flujo de información respecto a acciones que aporten desarrollo a la localidad y de paso, den crédito y credibilidad a la candidata por la alcaldía de Kennedy.
CATEGORÍA 5: Nombramiento sin relevancia (INDIRECTO)
En esta categoría se encuentra un tweet que habla de una acción realizada en el humedal, lo que lo convierte en agente indirecto, es decir, sin relevancia inicial para la investigación.
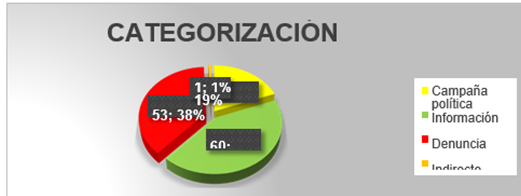
En las tablas 11, 12 y 13 se puede inferir el tipo de tweet con el que ha intervenido los congresistas, así como las menciones que se tienen en los mismos. La diferenciación de colores se creó bajo la siguiente convención que categoriza los tweets:
Tabla 11. Categorización de los tweetsTabla 12. Categorización de los tweetsTabla 13. Categorización de los tweets
CONCLUSIONES
A partir de la investigación realizada se pueden inferir diferencias que coinciden desde el inicio de la creación de un Bin consistente, con características que puedan robustecer su significado. Lo anterior se enuncia por el primer intento de búsqueda de información mediante la creación del Bin “ComuncaciónAmbiental” el cual, a la fecha de exploración no presentaba los datos necesarios y/o suficientes para llevar a cabo la investigación.
La investigación permite elucidar el grado de interés que presentan representantes políticos, focalizado en congresistas, por temas concretos del medio ambiente, siendo la denuncia, una de las categorías más atenuantes en la investigación. Así mismo, se demuestra cómo los intereses políticos, personales, llevan a reflexionar, así sea de forma momentánea el medio ambiente, para, de esta forma, poder sensibilizar a votantes y por supuesto lograr nuevos votos.
El flujo de información que representan las figuras públicas de base, entendidas como alcaldesa, presidente e instituciones, no logran evidenciar posturas, ni miradas críticas desde dentro hacia afuera; al contrario, presentan devenires de acciones no realizadas, omisiones, y acciones “involuntarias” frente a la temática de los humedales que estimulan la mención en los tweets representados.
El estudio de las redes sociales partiendo de un tema base, en este caso, la información que se genera a través de la palabra humedales, es interesante y ofrece una mirada amplia que solidifica las formas de informarnos de sucesos alrededor del tema. Permite abrir las redes de información al plantear hechos específicos que pueden ser abordados e investigados en otras redes. Así mismo, permite observar el movimiento de las redes que se tejen respecto a los temas de interés, articulándolo con la inmersión en la misma. Se pueden evidenciar sujetos públicos, privados, activistas, entidades y demás que comparten intereses de investigación e información similar a la personal, permitiendo ampliar las redes intercomunicativas de información e investigación de base.
REFERENCIAS
Grandjean, M. (2016). A social network analysis of Twitter: Mapping the digital humanities community. Cogent Arts & Humanities, 3(1), 1171458.
Hanneman, Robert A. and Mark Riddle. 2005. Introduction to social network methods. Riverside, CA: University of California, Riverside ( published in digital form at https://faculty.ucr.edu/~hanneman/nettext/) (Traducción en Español disponible en http://revista-redes.rediris.es/webredes/textos/Introduc.pdf)
Rogers, R. (2013). Digital Methods. Cambridge, MA: The MIT Press.
La aparición de “Big data” ha tenido un
desarrollo muy rápido en estos años, a la vez que aparecen otros conceptos
junto a éste como el “smart data” y en este artículo, Marcia Zeng presenta su entendimiento
con el “que”, “por qué”, “cómo” “dónde” y “cuáles” datos en relación con Smart data
y las humanidades digitales.
“QUE” es Smart data: Big data se ha caracterizado
por poseer múltiples “V´s”, , Volumen, Velocidad, Variedad y ha sido
complementado con Variabilidad y Veracidad. Big Data puede generar VALOR si se
utiliza apropiadamente. Esta última “V”, depende del “Smart data” que se puede
decir que se define como “la capacidad de lograr conocimientos desde datos veraces,
contextualizados, relevantes, cognitivos, predictivos y consumibles en
cualquier escala. (Kobielus, 2016, p. 8).
“POR QUË Smart data,
los datos en el siglo XXI son el activo más importante que puede generar valor
para quienes aprenden a extraerlos y usarlos. Los datos de este siglo son como
el petróleo del siglo XVIII, los datos rasos son como el crudo, y hay que
refinarlos y procesarlos para generar valor. De acuerdo con el reporte de “Digital
Universe” de 2012, únicamente el 3% de la información se encuentra etiquetada,
y solamente la mitad de este % está analizada. Por lo tanto, existen muchos datos
para ser conocidos, extractados y analizados. Y convertidos en Smart Data
CÓMO transformar
Big data en Smart data: existen muchas tecnologías que permiten convertir a Smart
data, entre ellas “cognitive computing, deep learning, machine learning,
artificial intelligence, predictive analytics, graph databases, machine
intelligence, voice processing, semantic technologies, autonomous vehicles, Big
Data, data science, Internet of Things (IoT), text analysis, Resource Description
Framework (RDF), knowledge graphs, contextual computing, Linked Data, deep
reasoning, ontologies, JSON-LD, common sense, natural language processing (NLP),
and semantic search” (DATAVERSITY, 2017). Todas estas tecnologías están interrelacionadas. Hoy tenemos ejemplos de
su uso en varias disciplinas, “IA” es una de las más avanzadas en este siglo.
QUIËN produce y utiliza Smart data: se
han realizado esfuerzos en utilizar Big data con las estrategias de Smart data
en varias disciplinas, ciencias naturales, ingeniería, análisis financieros,
negocios, medicina entre otros. En las humanidades el mundo de Smart data no ha
sido universalmente usado, aunque se han realizado proyectos de investigación
en estas ciencias. Zeng, presenta un cuadro resumen de actividades y recursos, así
como las tecnologías utilizadas en estas actividades de diversas ciencias.
DONDE está la marca distintiva en las
humanidades digitales: para Schöch (2013), la marca distintiva de Big data en
las humanidades parece ser un cambio metodológico más que una simple
tecnología. La visión de convertir Big data en Smart data, nos lleva de vuelta a
la conocida pirámide, “Data-Information-Knowledge-Wisdom (DIKW), dato – no
sabemos nada, información- el que, conocimiento – el cómo, y Wisdon – el porqué. (Zeleny, 1987; Ackoff, 1988), la
cual representa una forma básica de entender el mundo. Sin embargo la
aproximación a Smart data no es tan simple como replicar la trayectoria DIKW,
puesto que Smart Data está basado en metodologías de Big data, las cuáles nos
permiten llegar a conocer “unknown-unknowns”, (Borne 2013) (incógnitas desconocidas),en
vez de tomar el camino de “Known-unknown”, (incógnitas conocidas).
CUÁL data se puede encontrar para
investigación en Humanidades digitales: al tener Big data y Smart data en un
contexto de humanidades digitales un concepto clave que se debe tener claro es
el uso de “data”, o los datos. Es importante poder distinguir entre “data” y “digital
data”, los cuales no son equivalentes. En las fuentes de datos que existen a
través de LAMs, por sus siglas en inglés, “Libraries”, “Archives” y “Museums”,
y otras instituciones, así como tipos de datos diversos, en naturaleza,
calidad, y los más complejos para procesar, se tienen los datos no-estructurados
encontrados en documentos y otros tipos de textos digitalizados o no, y en toda
clase de formatos.
En el proceso de transformar datos
no-estructurados a datos estructurados o semiestructurados, la estrategia de
Smart Data conduce a los proveedores de servicios de datos a llegar a las máquinas
entendibles y no solamente las máquinas que leen datos. Esto con el fin de
procesar más eficientemente datos para las humanidades digitales. Los datos son
la entrada a cualquier investigación y las tecnologías que hoy se tienen soportan
análisis complejos de datos no estructurados que son los más comunes en las
humanidades.
Las tecnologías avanzadas de hoy bajo Big
data y Smart data permiten a los investigadores de las humanidades unirse a la
era digital con nuevas habilidades, utilizar grandes volúmenes de datos que tal
vez estaban ocultos y a reconstruir el pasado.
Preguntas:
¿Cómo lograr una buena transformación
los datos no – estructurados en datos para mi investigación?
¿Cómo determinar las incógnitas desconocidas
en mi investigación y lograr esa transformación de Big data en Smart data que
genere valor para la sociedad?
Referencias
Ackoff, R.L. (1989). From data to
wisdom. Journal of Applied Systems Analysis, 16(1), 3–9.
Borne, K. (2013). Big data, small
world: Kirk Borne at TEDxGeorgeMasonU [Video file].
Retrieved on December 15, 2016, from
https://www.youtube.com/watch?v=Zr02fMBfuRA.